Working with Probabilistic Data Labels to Train a Classifier

The Labeling Problem
The efficacy of a machine learning model is limited to the quality and quantity of data being used to train the model. The most powerful models typically require massive amounts of data to train. If the target variables in the model are categorical, there is an equally massive amount of labels in the dataset. Unfortunately, most of these labels are done by hand-- a painstakingly slow and resource intensive process. The time and resources that come with labeling datasets by hand creates inefficiencies in many machine learning pipelines. The categorical datasets that data scientists and programmers often learn from – such as those hosted on the UCI Machine Learning Repository or those preprocessed and uploaded to Kaggle – are idealized cases that do not reflect the typical reality of handling categorical data. In these datasets, someone has already taken the time to clean and process the data, providing the labels needed to train machine models. In real-life cases, this is usually not the case.
The origin of the categorical data labels often varies with the type of data in question. For example, pattern-recognition algorithms are often trained on labels provided through crowdsourcing. An algorithm trying to distinguish dogs from cats in images relies on humans to label each image beforehand. In ambiguous images, multiple people can assign different labels, resulting in a lower confidence for each category. On the other hand, medical diagnoses are often given in degrees of confidence either by some predefined test or by the doctor themselves. Similarly, natural language processing algorithms use confidence metrics to evaluate which definition of a word to employ (and, therefore, which meaning is intended) based on the context in which it is used. Despite the apparent categorical nature to these use cases, the reality can be quite the opposite.
Common in all of these cases is the association of a probability with the label. Whether the probability is simply an ensemble of multiple labels or intrinsic to the labeling methodology, the machine learning algorithms that train on these datasets must be able to handle probabilistic data labels. In some sense, the probability of a label is more informative than the label itself, as it also conveys the degree of confidence for a given observation. Understanding how to take advantage of this, and which approaches to handling these probabilistic data labels produce better models is a practical skill for data scientists and programmers encountering real-world categorical datasets. Additionally, tools that speed up or automate the labeling process in the machine learning pipeline resolve the inefficiencies that come with human labeling. Programmatically labeling is one such approach to do so.
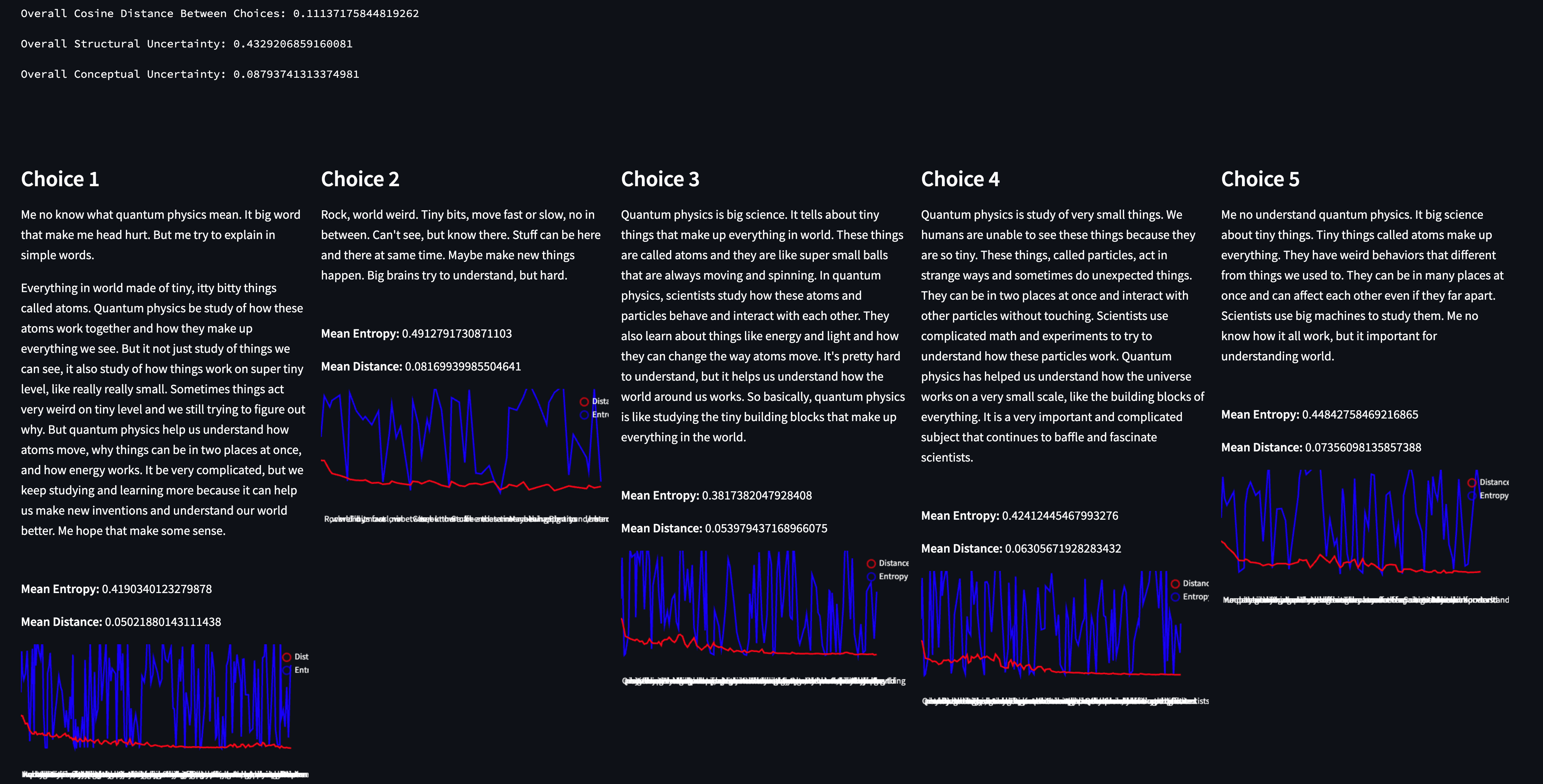
In this tutorial, I use Python to walk through several different approaches to using probabilistic data labels to train machine learning models. I use a dataset that has both probabilistic labels and true labels to show that, if the probabilistic labels are of high quality, they are more than sufficient in constructing high performance machine learning models.
Getting Started
To follow along with the code in this tutorial, you’ll need to have a recent version of Python installed. I use the Anaconda Navigator for all my programming needs, but the code used in this tutorial is generalized to work with any Python 3.7 distribution. To install Anaconda, go here. You can find all of the code and data used on my GitLab repository.
All of the packages I will be using are prebuilt into the Anaconda distribution, except for the Keras package. Keras provides us with the building blocks to construct our neural nets. To install for use in Anaconda, we can use conda-forge (you may also have to install conda-forge):
<pre><code class="language-python">conda install -c conda-forge keras</code></pre>
Alternatively, if you are using another Python distribution, you can install Keras with pip:
<pre><code class="language-python">pip install keras</code></pre>
To import the necessary packages and functions that we will use, in Python run:
<pre><code class="language-python">import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_recall_fscore_support
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from keras.models import Model
from keras import optimizers
from keras.layers import Input, Dense, Dropout</code></pre>
If any error indicates that a package cannot be found, simply install it using the same syntax as above, switching out the package name as needed.
The data I will be working with is the Enron Spam classification dataset from Kaggle. The dataset contains the text from 33,715 emails that are classified as either wanted (ham) or unwanted (spam). As can be seen below, the <pre class="inline"><code class="python">Text</code></pre> column contains the text of each email. We will use this text to train our model to classify the email as either ham or spam.
The <pre class="inline"><code class="python">Spam_Gold</pre></code> column contains the ‘gold’ labels included in the original .csv file from Kaggle: 0 for ham and 1 for spam. There is an additional column that is not in the original Kaggle dataset: the <pre class="inline"><code class="python">Spam_Pred</pre></code> column. This column contains probabilistic labels from 0 to 100 (rather than the binary labels in the <pre class="inline"><code class="python">Spam_Gold</pre></code> column) that indicate the probability of each email belonging to the spam class.
These probabilities were programmatically labeled using Watchful, without looking at the original gold labels. It would take days for a human to label each email to by hand, while Watchful accomplished this in around 3 hours.
To import the dataset, we can use the <pre class="inline"><code class="python">pandas</code></pre> package:
<pre><code class="language-python">file_path = 'watchful_export.csv'
email_df = pd.read_csv(file_path)
email_df.head()</code></pre>
The output should look something like this:

All set? Let’s go.
Exploring the Data
Before we get to the model implementation, it is always a good idea to explore the data we are working with. We can also compare the probabilistic data labels provided by Watchful with the original gold labels and evaluate how well the algorithm did. In most real-life cases, this is not possible, as the true labels are either limited to a few observations, not known at all, or have poor quality.
First, it is worth looking at the distribution of spam and ham emails in the gold labels and the probabilistic labels. This gives us an idea of the balance of the dataset, as well as how well the probabilistic labels match up to the gold labels.
<pre><code class="language-python">gold_col_name = 'Spam_Gold'
pred_col_name = 'Spam_Pred'
text_col_name = 'Text'
pct_spam = email_df[gold_col_name].sum() / email_df.shape[0]
pct_ham = 1 - pct_spam
pct_spam, pct_ham</code></pre>

So, the dataset has nearly an equal distribution of spam and ham emails. Dealing with sparse data is not trivial for most machine learning algorithms. Fortunately, we don’t have to worry about it. As, expected, the histogram of gold labels is nearly equal in height:
<pre><code class="language-python">plt.hist(email_df[gold_col_name])
plt.show()</code></pre>

And for the probabilistic labels:
<pre><code class="language-python">plt.hist(email_df[pred_col_name])
plt.show()</code></pre>

The distributions are pretty similar. This is an indication that the probabilistic labels assigned by Watchful are well aligned with the gold labels – a promising sign for being solely generated by the email text.
From a qualitative perspective, certain characteristics of the emails are bound to correlate with either being spam or ham. For example, one could imagine that curt, plain text is probably not an advertisement for some product and is therefore an indicator of a ham email. On the other hand, text that is long and superfluous is generally more common in advertisements, and may indicate a spam email.
To get an idea of the distribution of the number of words used in the emails, we can take advantage of Python’s list comprehension syntax:
<pre><code class="language-python">lengths = np.array([len(doc.split()) for doc in email_df[text_col_name]])
pd.DataFrame(lengths).describe()</code></pre>

And to visualize the email length distribution:
<pre class="inline"><code class="language-python">plt.hist(lengths[lengths < 1000])</code></pre>
<pre class="inline"><code class="language-python">plt.show()</code></pre>

The distribution is heavily skewed, as expected for a text-based communication medium – most emails are relatively short, and the probability of a longer email scales inversely with the length. It is also worth looking at the number of unique words used in each email. This distribution should mimic the right-skewed distribution of the email word length.
<pre><code class="language-python">vocabs = np.array([len(set(doc.split())) for doc in email_df[text_col_name]])
pd.DataFrame(vocabs).describe()</code></pre>

<pre><code class="language-python">plt.hist(vocabs[vocabs < 500])
plt.show()</code></pre>

The distribution is reasonable relative to the email length distribution. One would expect that common articles (‘a’, ‘the’, ‘and’, etc.) are repeated several times in a given email, and the true number of unique words is 2-4x lower than the total number of words. We can also check how well the probabilistic labels align with the gold labels, assuming a probability higher than 50% indicates a spam.
<pre><code class="language-python">email_df[pred_col_name] = email_df[pred_col_name].apply(lambda r: 0 if r < 50 else 1)
accuracy_score(email_df[gold_col_name], email_df[pred_col_name], True)</code></pre>

The agreement is pretty good assuming a simple 50% threshold. When handling classification data, accuracy is not the only important metric in evaluating how well a given model performs (in this case, the underlying model used by Watchful to create the probabilistic labels).
The precision, or the ability of the classifier not to label as positive a sample that is negative, is the ratio of true positives to the total number of true positives and false positives. The recall, or the ability of the classifier to find all the positive samples, is the ratio of true positives to the total number of true positives and false negatives. The F-score is a metric that combines the two, albeit with the appropriate weighting, that ranges between 0 (for worse models) to 1 (for better models).
Fortunately, there is a built in function in the <pre class="inline"><code class="language-python">sklearn</pre></code> package that can calculate these metrics:
<pre><code class="language-python">precision_recall_fscore_support(email_df[gold_col_name], email_df[pred_col_name])</code></pre>

The first row is the precision, followed by the recall, F-score, then total number of labels. The columns indicate first ham (or the 0 label), then spam (the 1 label). As we first suspected in our exploratory analysis, the probabilistic labels seem to reflect the gold labels quite well. We can use this to our advantage when training our model.
Training on the Thresholded Probabilistic Labels
As we established in our exploratory analysis, the probabilistic labels reflect the gold labels with a high degree of accuracy. In many real-life cases, the labeling methodology used to create the gold labels creates inefficiencies in the data pipeline. Tools like those provided by Watchful can be used to create probabilistic labels that can be used to train machine learning models instead of using the gold labels. There are a few strategies that can be used to implement this: the first is to simply threshold the probabilistic labels.
To get started, I re-import the dataset and rescale the <pre class="inline"><code class="language-python">Spam_Pred</code></pre> column to mirror the range of the <pre class="inline"><code class="language-python">Spam_Gold</code></pre> column:
<pre><code class="language-python">email_df = pd.read_csv(file_path)
email_df[pred_col_name] /= 100
email_df.head()</code></pre>
The output should look something like this:

And now we need to split the dataset into a test and training set:
<pre><code class="language-python">df_train, df_test = train_test_split(email_df.sample(frac=1), test_size=0.2)</pre></code>
A common strategy for handling text data in machine learning models is to vectorize it. In other words, we need to convert the raw text to a form that the model can understand (in our case, a neural net). To do so, the sklearn package has a myriad of built-in functions. I use TfidVectorizer to convert the raw text to a matrix of TF-IDF features:
<pre><code class="language-python">vec = TfidfVectorizer(analyzer='word', ngram_range=(1, 1))
X_train = vec.fit_transform(df_train[text_col_name])
X_test = vec.transform(df_test[text_col_name])
ip_dim = X_train.shape[1]</code></pre>
To implement a 50% thresholding on the predicted labels:
<pre><code class="language-python">y_train = np.stack([df_train[pred_col_name].apply(lambda r: 0 if r >= 0.5 else 1),
df_train[pred_col_name].apply(lambda r: 1 if r >= 0.5 else 0)], -1)
y_test = df_test[gold_col_name].to_numpy()
probs = df_train[pred_col_name].apply(lambda r: r if r > 0.5 else 1 - r).to_numpy()</code></pre>
For the neural net, we need everything to be a <pre class="inline"><code class="language-python">numpy</code></pre> array. Notice that we also define a <pre class="inline"><code class="language-python">probs</code></pre> variable that will serve as our sample weight when training the neural net. In this way, the probabilistic labels that are closer to the 50% threshold that we applied have a lower weight (when calculating the loss function during training) than those labels that are close to either 0 or 1.
The structure of the neural net is as follows. The input layer instantiates a Keras tensor (the form needed for the inputs and outputs of the model) with the same dimension as the sparse matrix created by vectorizing the text data. The first layer is a fully connected layer with 128 units and no activation function (i.e. linear). The second layer consists of 64 units with relu activation. The third layer is a dropout layer to prevent overfitting during training. And finally, an output layer of just 2 units (because we only have 2 categorical labels) with softmax activation.
Once we set up each layer, we can specify the inputs and output layers for the Keras model, then specify the losses and metrics we want with the compile method.
<pre><code class="language-python">x = Input(shape=(ip_dim,))
h1 = Dense(128)(x)
h2 = Dense(64, activation='relu')(h1)
h3 = Dropout(0.1)(h2)
h4 = Dense(2, activation='softmax')(h3)
model = Model(inputs=x, outputs=h4)
model.compile(optimizers.Adam(0.00001), 'categorical_crossentropy', ['accuracy'])</code></pre>
The Adams optimizer is a stochastic gradient descent method that is not too computationally intensive. Using cross entropy for the loss function is standard for classification and the accuracy metric is the most general metric to see that training is in fact improving the model.
Now, to train the neural net with cross-validation:
<pre><code class="language-python">model.fit(X_train, y_train, epochs=20, validation_split=0.15, sample_weight=probs)</code></pre>
The output of the first epoch should look something like this:

Additional output metrics for each epoch should appear showing the increase in accuracy and decrease in loss. Once training is complete, we can use the model to predict on the <pre class="inline"><code class="language-python">X_test</pre></code> set and compare to the true gold labels:
<pre><code class="language-python">y_pred = np.argmax(model.predict(X_test), -1)
accuracy_score(y_test, y_pred)</code></pre>

Not a bad accuracy. We also calculate the precision, recall, and F-score:
<pre><code class="language-python">precision_recall_fscore_support(y_test, y_pred)</code></pre>

Training Directly on the Probabilistic Labels
A second strategy for using probabilistic labels is to train directly on the probabilities without implementing any thresholding. To do so, we use the same vectorizer to convert the text data to the sparse matrices containing TF-IDF statistics:
<pre><code class="language-python">vec = TfidfVectorizer(analyzer='word', ngram_range=(1, 1))
X_train = vec.fit_transform(df_train[col_text])
X_test = vec.transform(df_test[col_text])
ip_dim = X_train.shape[1]</code></pre>
Instead of applying a threshold and forcing the probability labels to either 0 or 1, we maintain the probability value in the training set. To do so, the probability of ham (or 0) is simply 1- (probability of being 1):
<pre><code class="language-python">y_train = np.stack([df_train[col_pred].apply(lambda r: 1 - r), df_train[col_pred]], -1)
y_test = df_test[col_gold].to_numpy()</code></pre>
We construct a neural net with identical structure to the previous one:
<pre><code>x = Input(shape=(ip_dim,))
h1 = Dense(128)(x)
h2 = Dense(64, activation='relu')(h1)
h3 = Dropout(0.1)(h2)
h4 = Dense(2, activation='softmax')(h3)
model = Model(inputs=x, outputs=h4)
model.compile(optimizers.Adam(0.00001), 'kullback_leibler_divergence', ['accuracy'])</code></pre>
Since we no longer have two categorical labels, we use the Kullback-Leibler divergence (or relative cross entropy) for continuous probabilities to calculate the loss. This is very similar to the cross entropy function used previously. To train the model:
<pre><code class="language-python">model.fit(X_train, y_train, epochs=20, validation_split=0.15)</code></pre>
The output should look similar to before:

Then to make predictions on the test set:
<pre><code class="language-python">y_pred = np.argmax(model.predict(X_test), -1)</code></pre>
And compare them to the gold labels:
<pre><code class="language-python">accuracy_score(y_test, y_pred)</code></pre>

Not bad. A bit better than training on the thresholded labels. We can also compare the precision, recall and F-score to the previous thresholding results:
<pre><code class="language-python">precision_recall_fscore_support(y_test, y_pred)</code></pre>